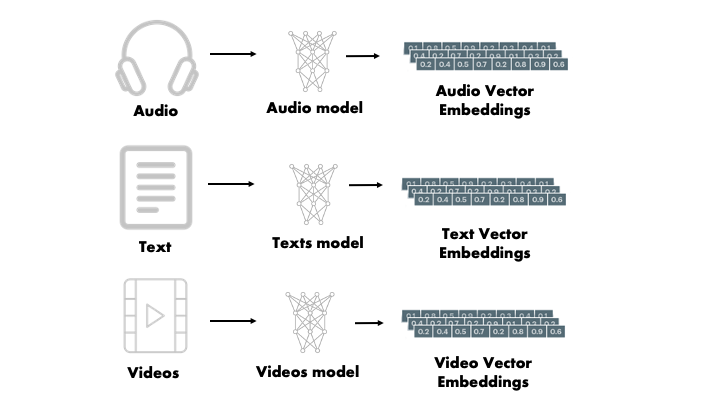
Vector What?
We’re all talking about Large Language Models (LLMs) such as OpenAPI’s GPT-4. What may not be widely appreciated is that these LLMs are dependent on a technique called vector embedding. Vector embedding is simply the encoding of content, be that audio, images, video or text, into a vector of numbers. However, unlike encoding schemas such MP3 or JPEG which directly represent the content, vector embedding aims to also encode the semantics, i.e. meaning, of the content. Such an encoding allows content to be retrieved based on similar meanings and concepts.
How Does Vector Encoding Work?
Probably the easiest way to explain vector embedding is via a coded example. It starts with a pre-trained LLM model that’s specifically designed as a content token transformer. These are LLMs that have been specifically adapted and tuned to transform content into vectors. One widely used such model is Sentence-BERT, as the name suggests adapted from Google BERT. Sentence-BERT has been made available in a Python library called SBERT. Below is a code snippet that transforms three sentences.
!pip install -U sentence-transformers
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
sentences = ['A man is eating food.',
'A man is eating a piece of bread.',
'The girl is carrying a baby.',
'A man is riding a horse.',
'A woman is playing violin.',
'Two men pushed carts through the woods.',
'A man is riding a white horse on an enclosed ground.',
'A monkey is playing drums.',
'Someone in a gorilla costume is playing a set of drums.'
]
embeddings = model.encode(sentences)
for sentence, embedding in zip(sentences, embeddings):
print("Sentence:", sentence)
print("Embedding:", embedding)
print("")
Running this code prints out a set of arrays containing floating point numbers that have codified the tokens and semantics of the four sentences.
Semantic Similarity through Vector Computation
Once content has been converted to vectors through a Transformer LLM, operations can be carried out over these vectors to determine how similar content is or whether content is clustered around common topics. These computations generally work on vector distance calcuations of which there are six primary types.
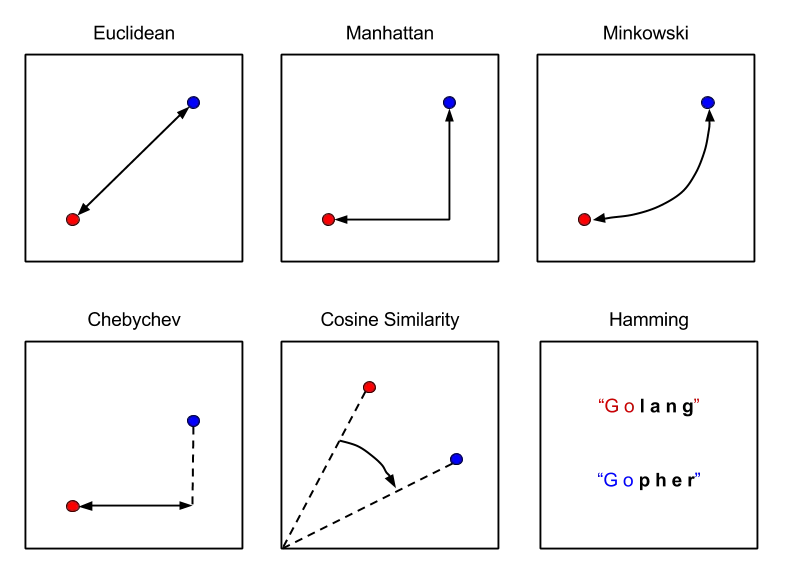 The code below uses Cosine Similarity to determine whether the sentences above are semantically similar to each other.
The code below uses Cosine Similarity to determine whether the sentences above are semantically similar to each other.
from sentence_transformers import util
cos_sim = util.cos_sim(embeddings, embeddings)
#Compute cosine similarity between all pairs
cos_sim = util.cos_sim(embeddings, embeddings)
#Add all pairs to a list with their cosine similarity score
all_sentence_combinations = []
for i in range(len(cos_sim)-1):
for j in range(i+1, len(cos_sim)):
all_sentence_combinations.append([cos_sim[i][j], i, j])
#Sort list by the highest cosine similarity score
all_sentence_combinations = sorted(all_sentence_combinations, key=lambda x: x[0], reverse=True)
print("Top-5 most similar pairs:")
for score, i, j in all_sentence_combinations[0:5]:
print("{} \t {} \t {:.4f}".format(sentences[i], sentences[j], cos_sim[i][j]))
This provides the result:
Top-5 most similar pairs:
A man is eating food. A man is eating a piece of bread. 0.7553
A man is riding a horse. A man is riding a white horse on an enclosed ground. 0.7369
A monkey is playing drums. Someone in a gorilla costume is playing a set of drums. 0.6433
A woman is playing violin. Someone in a gorilla costume is playing a set of drums. 0.2564
A man is eating food. A man is riding a horse. 0.2474
Pretty reasonable result I would propose.
Semantic Search
Now we’ve demonstrated similarity we can carry out semantic search. Take the following code.
import torch
embedder = SentenceTransformer('all-MiniLM-L6-v2')
# Corpus with example sentences
corpus = ['A man is eating food.',
'A man is eating a piece of bread.',
'The girl is carrying a baby.',
'A man is riding a horse.',
'A woman is playing violin.',
'Two men pushed carts through the woods.',
'A man is riding a white horse on an enclosed ground.',
'A monkey is playing drums.',
'A cheetah is running behind its prey.'
]
corpus_embeddings = embedder.encode(corpus, convert_to_tensor=True)
# Query sentences:
queries = ['A man is eating pasta.', 'Someone in a gorilla costume is playing a set of drums.', 'A cheetah chases prey on across a field.']
# Find the closest 5 sentences of the corpus for each query sentence based on cosine similarity
top_k = min(5, len(corpus))
for query in queries:
query_embedding = embedder.encode(query, convert_to_tensor=True)
# We use cosine-similarity and torch.topk to find the highest 5 scores
cos_scores = util.cos_sim(query_embedding, corpus_embeddings)[0]
top_results = torch.topk(cos_scores, k=top_k)
print("\n\n======================\n\n")
print("Query:", query)
print("\nTop 5 most similar sentences in corpus:")
for score, idx in zip(top_results[0], top_results[1]):
print(corpus[idx], "(Score: {:.4f})".format(score))
And the results:
======================
Query: A man is eating pasta.
Top 5 most similar sentences in corpus:
A man is eating food. (Score: 0.7035)
A man is eating a piece of bread. (Score: 0.5272)
A man is riding a horse. (Score: 0.1889)
A man is riding a white horse on an enclosed ground. (Score: 0.1047)
A cheetah is running behind its prey. (Score: 0.0980)
======================
Query: Someone in a gorilla costume is playing a set of drums.
Top 5 most similar sentences in corpus:
A monkey is playing drums. (Score: 0.6433)
A woman is playing violin. (Score: 0.2564)
A man is riding a horse. (Score: 0.1389)
A man is riding a white horse on an enclosed ground. (Score: 0.1191)
A cheetah is running behind its prey. (Score: 0.1080)
======================
Query: A cheetah chases prey on across a field.
Top 5 most similar sentences in corpus:
A cheetah is running behind its prey. (Score: 0.8253)
A man is eating food. (Score: 0.1399)
A monkey is playing drums. (Score: 0.1292)
A man is riding a white horse on an enclosed ground. (Score: 0.1097)
A man is riding a horse. (Score: 0.0650)
Again, pretty impressive I would propose.
Vector Databases
Leveraging these Transformer Models is a new generation of database engines, namely Vector Databases. You’re probably familar with Relational Databases and probably newer database types such as NoSQL Document, Key-Value Store and Graph. So how do Vector Databases differ?
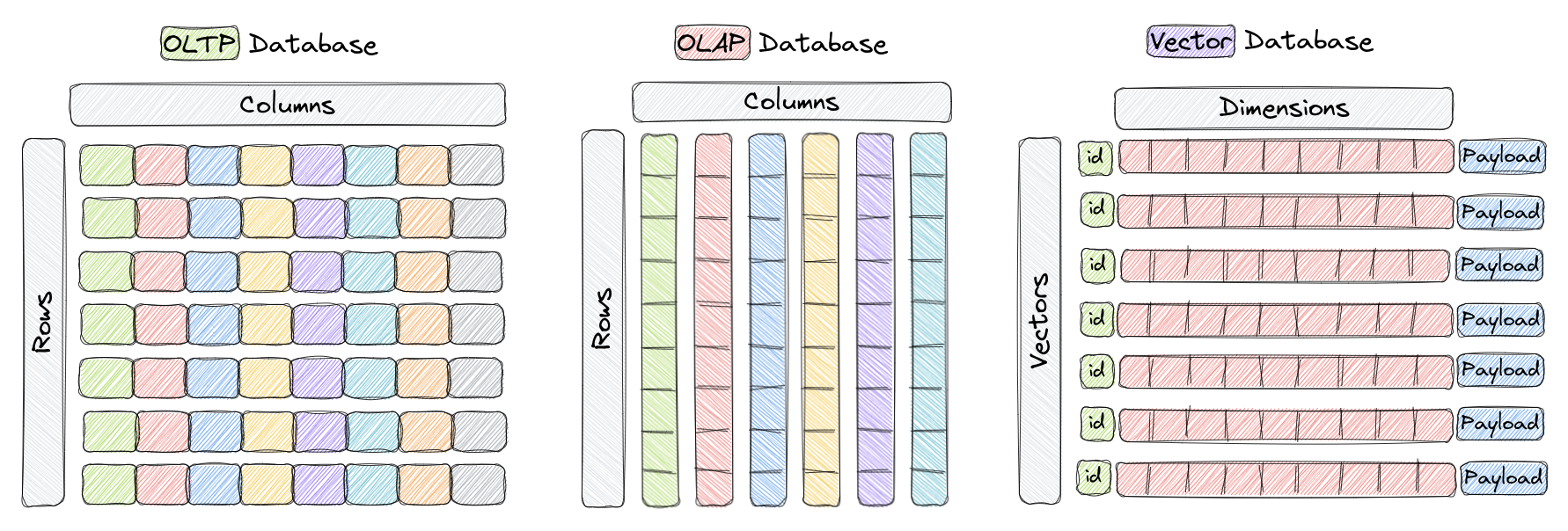
Instead of storing rows and columns, Vector Databases natively store and query vectors. These vectors are then associated with one or more content / payload items, for example images, audio, text etc. Their architecture is then optimised for compute against these high dimensional spaces and capable of interoperability with Machine Learning models such as LLMs.
There are a number of Vector Databases becoming available, as with everything Digital these days a number are only available as Cloud services. However, there are a number of Open Source Vector Databases that can be deployed locally. One such I’ve been experimenting with is Qdrant. It’s architecture is shown below.
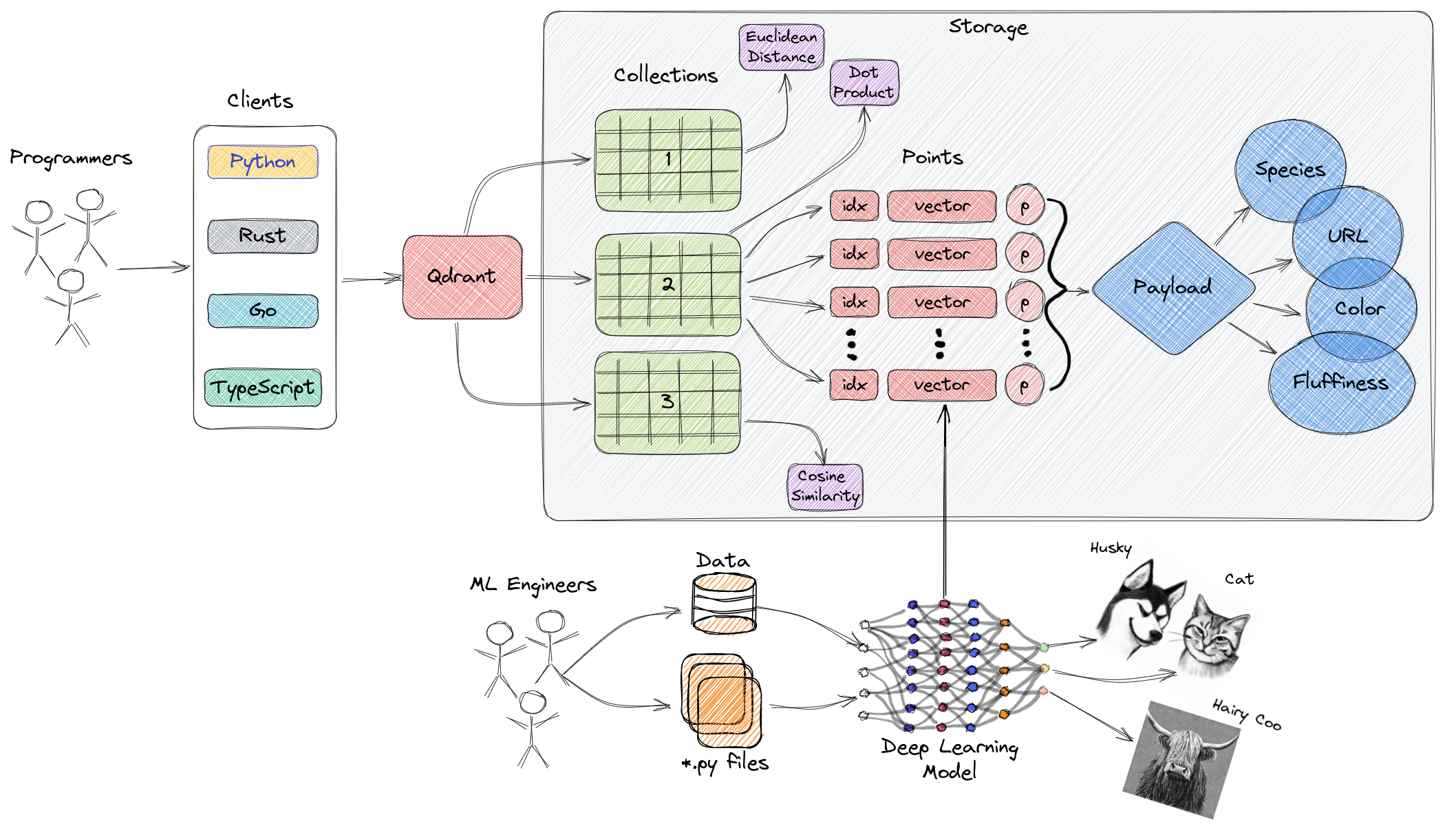 The workflow for most Vector Databases is similar to Qdrant and is generally as follows:
The workflow for most Vector Databases is similar to Qdrant and is generally as follows:
- Acquire the corpus dataset
- Transform the corpus into a vector space (using transformers such as SBERT)
- Build a vector space model of the corpus
- Upload this model to the Vector Database
- Build and deploy a query API
Integrating with the wider LLM Ecosystem
As Vector Databases are close near neighbours to Machine Learning and LLMs there’s generally good intergration and interoperability with the wider AI ecosystem. For example Qdrant, as a number of other Vector Databases, supports integration with LangChain. This allows you to incorporate a Vector Database backend to LLM enabled applications.
The Future of Vector Databases
The vast majority of Digital content, both on the Internet and increasingly within Enterprises, is unstructured. Traditional database architectures, even Document Databases such as MongoDB, are not well equiped to cope with this, particularly with the rise of LLMs. I for one, can only see a positive future and up take in Vector Databases.
If you’re interested in my experiment with Qdrant check out my GitHub repo.