-
-
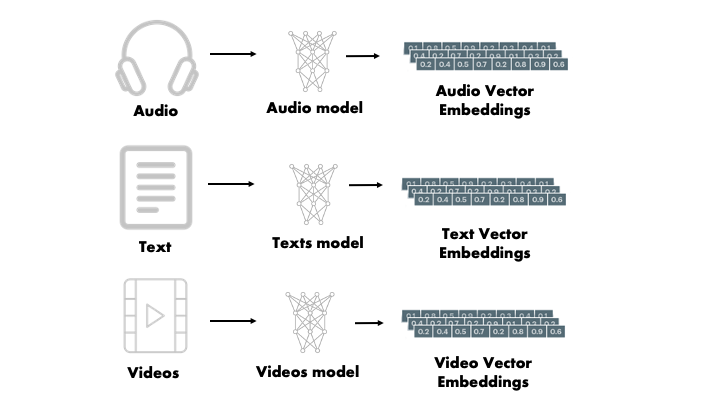
Vector What?
We’re all talking about Large Language Models (LLMs) such as OpenAPI’s GPT-4. What may not be widely appreciated is that these LLMs are dependent on a technique called vector embedding. Vector embedding is simply the encoding of content, be that audio, images, video or text, into a vector of numbers. However, unlike encoding schemas such MP3 or JPEG which directly represent the content, vector embedding aims to also encode the semantics, i.e. meaning, of the content. Such an encoding allows content to be retrieved based on similar meanings and concepts.
How Does Vector Encoding Work?
Probably the easiest way to explain vector embedding is via a coded example. It starts with a pre-trained LLM model that’s specifically designed as a content token transformer. These are LLMs that have been specifically adapted and tuned to transform content into vectors. One widely used such model is Sentence-BERT, as the name suggests adapted from Google BERT. Sentence-BERT has been made available in a Python library called SBERT. Below is a code snippet that transforms three sentences. ```python !pip install -U sentence-transformers from sentence_transformers import SentenceTransformer model = SentenceTransformer(‘sentence-transformers/all-MiniLM-L6-v2’)
-
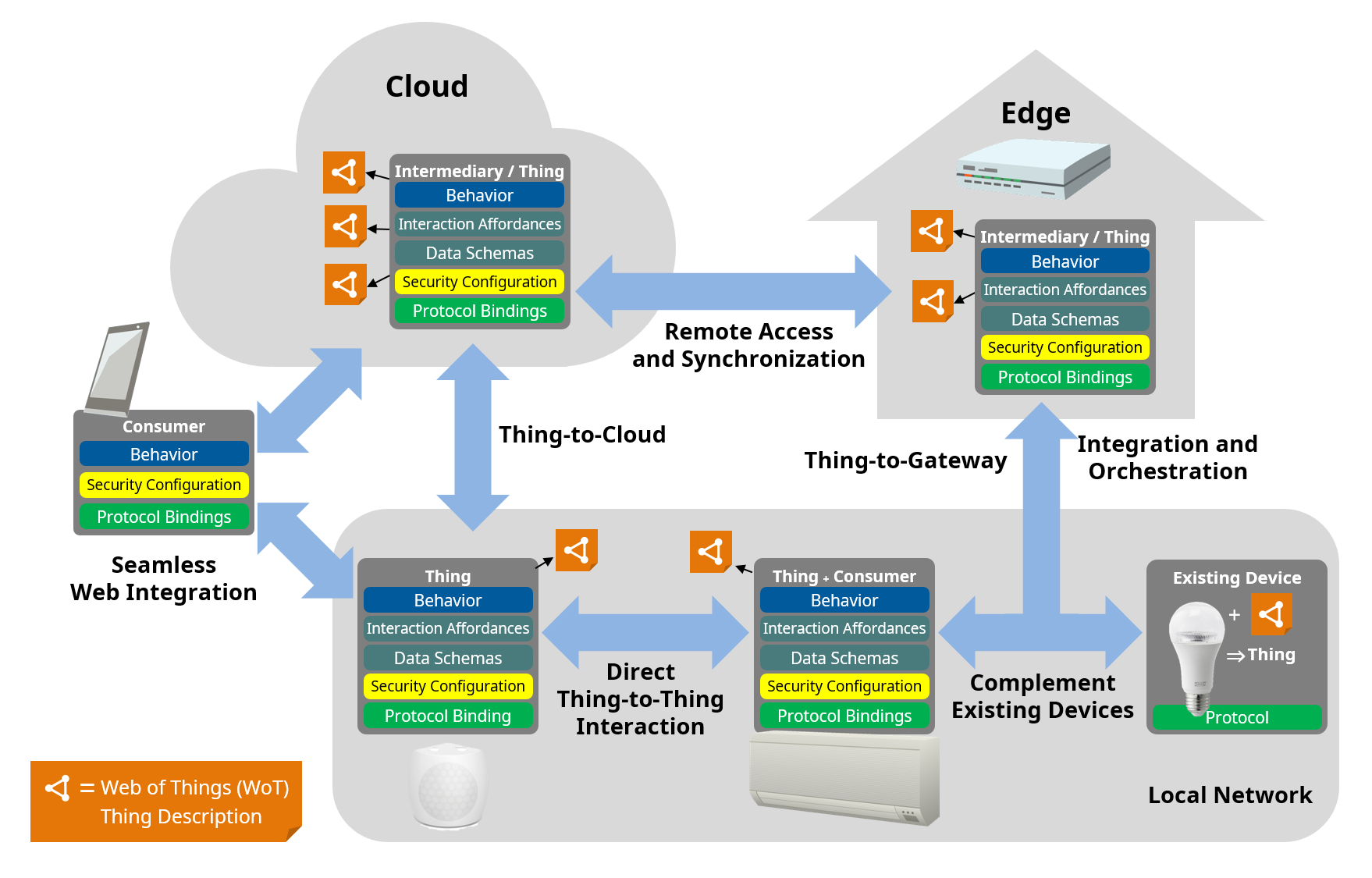
Digital Twins - just what are they again?
Digital Twin is possibly one of the most overused and confused terms used in the world of “Digital”. It seems to get applied to almost anything and everything. In my personal view a Digital Twin needs to have the following properties:
- A real world physical asset, such as a building, vehicle or machine tool.
- The asset acquires data about itself through sensors such as acceleration, temperature and so on.
- One or more synthetic models for the asset and/or it’s subsystems have been developed. These models are typically used to predict and simulate the behaviour of the asset and it’s subsystems.
- The asset has communications connectivity to allow data acquired from sensors to be sent back to the synthetic models.
- The synthetic models can make use of the real-world sensor data to improve the performance and operation of the asset as well as improve the models themselves. For example support fault diagnostics, predictive maintenance / prognostics, inform a proposed design modification or new product design and so on.
-

Clean (Hexagon / Onion) Architecture
There’s been a shift to Microservices and Domain Driven Design for a number of years now. Predominately driven by the complexity and ability to adapt to rapid change demanded by Internet scale systems such as Amazon and Netflix. In this article, I’d like to put forward the view that all software should be designed to these principles.
-

Measuring Motion through Optics
I’ve been looking to add motion and velocity estimation to my 4WD IoT Robot for a while. The current motors do not have rotary encoders and there isn’t the space to install seperate ones, so I was looking for another approach. I did look at estimation through combing an IMU, Kalman Filter and GPS fixes, when I get them, but that felt like it wasn’t going to be accurate enough. Therefore, I started to look at Optical Flow Sensing.
-
Explaining AI - From First Principles with Python
As we all know, AI is everywhere. However I’ve been increasingly concerned that the field is not very widely understood and is subject to considerable levels of misunderstanding. I think the Tech industry, consultancies and vendors don’t help here with all the buzz and hype.
-

Meet Robot Gordon
I haven’t posted on my lockdown IoT AI at the Edge project for a while, so here’s an update. I decided a “static” 4G GNSS STM32 based device wasn’t enough, so I’ve got it moving on a 4WD autonomous vehicle. Well, right now semi-autonomous, but the plan is to aim to get to a fully autonomous vehicle in increments.
-

Father of UNIX, C and software as we know it
Not as well known as Steve Jobs, Bill Gates, but Dennis Ritchie is argubly more significant to the development of modern computing. SO, I thought I’d recount Dennis’s story and my take on his contribution.
-

There’s a lot more to GPS than you think
For a start, the correct term is GNSS, Global Navigation Satellite System, GPS is used to refer to the US system, which is actually called NAVSTAR. There are five other GNSS nation operated systems:
- GLONASS (Russia)
- Galileo (European Union)
- BeiDou (China)
- NavIC (India)
- QZSS (Japan)
-

Why PHP for REST API?
I currently run this website on a pretty small 1 vCPU 512MB environment on AWS and it’s perfectly fine for a statically generated website such as this. In fact with AWS’s CDN it’s proven to be very fast. This is the real joy of static site generators such as Jekyll over classic database driven CMS environments such as WordPress, along with being substantially more secure. In fact as a static site is really all about network and storage I/O, the CPU utilisation has bearly risen above 0.2%. The idea of deploying my website to a VPC environment rather than shared hosting or S3, was that I’d have a Cloud ‘sandpit’ for other projects and experiments.
I thought I’d share my experience of building an REST API using PHP and provide a bit of a tutorial and hints and tips for anyone else out there wanting to do something similar.
The Technical Platform
The technical platform is NGINX on Amazon Linux AMI with PHP-FPM deployed on UNIX sockets. So given I didn’t want to go the expense of increasing my Cloud resources and costs, I decided I’d leverage the base environment to build my REST API server. I have been doing a lot of development in Python recently, for both Data Science and APIs. I’ve become a fan of OpenAPI 3.0 and have been using the Flask based Connexion OpenAPI framework.
Once I knew I was going to be building on PHP (7.2) I started to look around for a REST API framework. Swagger OpenAPI Generator supports PHP for the Slim framework, but I’m not a fan of Slim. Also the code generated for the Slim framework didn’t really provide that much acceleration or OpenAPI 3.0 validation. Nowhere near as much as the Python Connexion framework supports. However, deploying a Python Flask based runtime didn’t seem to make sense. I would just take another slice of memory. Also integrating HTTPS SSL with NGINX to PHP-FPM was going to be simpler than setting up a reverse proxy to a Flask server.
It’s been a while since I’ve done much development in PHP so I trawled the web for the current state of PHP MVC frameworks. In the end I opted for CodeIgniter 4.0. I’ve used CodeIgniter 3.0 in the past and have liked it’s balance of performance, ease of use and minimalism, yet is still feature rich.
MySQL / MariaDB is normally the database of choice with PHP, however MySQL is quite a memory hog. Although I have enough physical memory space to deploy MySQL I figured that it would take away cache being used by NGINX and so impact my website performance. So, I opted for the simpler route of SQLite3. Given the transaction volumes I am planning to put through this service, SQLite3 should be good enough, particularly as it’s deployed on a fast SSD.
A Quick Note on the PHP Debate
Historically PHP was seen by a lot of Software Engineers as a poor relation to languages such as C++, Java, Python and, more recently, NodeJS for backend web development.
PHP originally started out as an interpreted scripting language for Web Servers,. It suffered from weak typing and “spaghetti code” websites. However over the years it’s evolved and addressed a lot of the original deficiencies and criticisms. With the advent of PHP 7.x and the PHP-FPM daemon it’s also become a pretty performant platform. Even in 2020, with the rise of platforms such as NodeJS, Ruby and Go, ~80% of the Web is powered by PHP enabled sites - a lot of these are likely to be CMS platforms such as WordPress and Dupal. Even so, that’s a serious figure.
-

Fly Me to the Moon - by code
It was great to see the succesful launch and docking of SpaceX Dragon Crew last week, marking the return to US manned space launch. That event got me thinking back to the Apollo programme and one of my favourite aspects the Apollo Guidance Computer (AGC)
-

The CPU Architecture you’ve probably never of heard of, but soon will
Everyone’s familar with Intel and their x86 architecture, it’s been the dominant workstation and server class CPU architecture for the last 40 years. And then there’s ARM, the plucky Brit startup that took on the major US Chip manufacturers and dominated the Mobile and Microcontroller classes. The dominance of these two CPU architectures hasn’t left much room for any other players, probably IBM’s PowerPC is the only one that comes close, but today is a small niche player.
-

This is slow
One of the first sensors I hooked up to my IoT board was a DHT 11 combined temperature and humidity sensor. This is quite a popular low cost sensor widely used in the Arduino and Makers community. As you’d expect, there are a number of DHT sensor libraries around and, of course, not one to reinvent the wheel, I deployed one to test it out. It worked, great. However, I noticed it was quite slow on response reading the data back on the bus.
-

The Original Digital Twin
Today we are bombarded with the concept of the “Digital Twin”. Digtial Twins are everywhere. However, it appears to me that everyone has a different opinion of what a Digital Twin is and is not (this is definitely a subject for a future article). If we can agree that, simply put, a Digital Twin is no more than a software representation of some real world “thing”, then Digtial Twins have been around since pretty much the birth of modern digital computing.
-

Choices, Choices
Building an AI capable IoT Edge Device has been on my To-Do list of personal projects for a while. I’ve finally got round to getting a project up and running.
-

5mn IC Fab the Limit?
The core technology underpinning modern Microprocessor design and fabrication has bearly changed since the first integrated Circuit was developed by Jack Kilby in 1958.
-

All Hail to the Summit!
The US has recently wrestled back the HPC Super Computer Crown from China with Summit, a 200 PetaFLOP Goliath with over 9000 22-core PowerPC CPUs and a mind boggling 27,000 NVIDA Tesla V100 GPUs.
-
The Need for Circular Bufffers
I’m currently working on a project where I need to (i) cope with very high data rates over a shared memory buffer and (ii) squeeze as much processing power out of the (pretty low power) CPU as I possibly can. Oh, it’s going to have to be multi-threaded.